Saved for future reference from kottke.org:
the Long Tail of Life: During an 11 month study in 2007, scientists sequenced the genes of more than 180,000 specimens from the Western English Channel. Although this level of sampling "far from exhausted the total diversity present," they wrote, one in every 25 readings yielded a new genus of bacteria (7,000 genera in all).
See also: Venter sequences the Sargasso Sea (and download the dataset here!); a review on the emerging field of metagenomics; genomic databases at NCBI (sequences of everything from the human genome to three strains of ebola); Helicos high-speed sequencing; a nice powerpoint on next-gen short-read sequencing and sequence assembly (including notes on Eulerian walks on De Bruijn graphs, the method used by sequence assembly algorithms like Velvet.) Man, guys, sequencing is the coolest.
Showing posts with label technology. Show all posts
Showing posts with label technology. Show all posts
Friday, April 23, 2010
Monday, April 12, 2010
Bicycle Built for Two Thousand
Bicycle Built For 2,000 is comprised of 2,088 voice recordings collected via Amazon's Mechanical Turk web service. Workers were prompted to listen to a short sound clip, then record themselves imitating what they heard. (more info)
(Daisy Bell was famously performed by an IBM 704 in 1962, in the world's first example of musical speech synthesis-- which is probably why Kubrick chose it for the end of 2001 as well.)
(Daisy Bell was famously performed by an IBM 704 in 1962, in the world's first example of musical speech synthesis-- which is probably why Kubrick chose it for the end of 2001 as well.)
Thursday, January 7, 2010
2020 Visions
Nature's interviews of prominent scientists on their visions of scientific progress in the next decade. Exciting stuff!
Tuesday, December 22, 2009
Pitman Shorthand

(source)
Pitman shorthand is a system of shorthand for the English language developed by Englishman Sir Isaac Pitman (1813–1897), who first presented it in 1837. Like most systems of shorthand, it is a phonetic system; the symbols do not represent letters, but rather sounds, and words are, for the most part, written as they are spoken.
Tuesday, December 15, 2009
Algorithm Design
In scientific computing, optimality of algorithms is not always something which receives full consideration by users-- if you want to run a sort or solve some combinatorial problem, you are more concerned with making the algorithm work than looking into how fast it runs. But in dealing with very large data sets, reducing the limiting behavior of your algorithm from N^2 to NlogN can reduce your runtime from something on the order of years to something on the order of seconds. So while there are many computational problems out there for which solutions are known to exist, the practical matter of implementing such solutions is so expensive that they are effectively useless-- but if a new algorithm could be found which would reduce their runtime, we might suddenly be able to use them.
This is the driving motivation behind much of the work that goes into quantum computing. Because bit state in a quantum computer is probabilistic rather than binary, the computer operates in a fundamentally different way, and we can design algorithms which take such differences into account. One vivid example is Grover's Algorithm for searching an unsorted array. Here's a good description from Google labs:
So if you were opening one drawer a second, the traditional algorithm would take you an average of six days to run, while the quantum algorithm would take you a little under 17 minutes.
(Now, say each of those million drawers represented a different combination of letters and numbers, and you were trying to find the drawer/combination which corresponded to the password to someone's email account. Encryption standards which would be secure against attacks from a traditional computer are easily bypassed by quantum algorithms.)
While quantum computing still has a ways to go, parallel programming is already providing another alternative to traditional computer architecture. In parallel programming, you split your code up and send it to a number of computers running simultaneously (for our million-drawer problem: say you had 9 other people to help you, you could each search a different set of 100,000 drawers and it would only take 50,000 steps on average for the ball to be found.) So the trick in parallel programming is to figure out the right way to eliminate all the bottlenecks in your code and split up your task across processors as efficiently as possible.
Now, what about a task like image recognition? If you had a couple thousand processors at your disposal and a single image to feed them, what is the most efficient way for your processors to break up that image so that between them they can reconstruct an understanding of what it depicts? You might decide to give each computer a different small piece of the image, and tell it to describe what it sees there-- maybe by indicating the presence or absence of certain shapes within that piece. Then have another round of computers look at the output of this first batch and draw more abstract conclusions-- say computers 3, 19, and 24 all detected their target shape, so that means there's a curve shaped like such-and-such. And continue upwards with more and more tiers representing higher and higher levels of abstraction in analysis, until you reach some level which effectively "knows" what is in the picture. This is how our current understanding of the visual cortex goes-- you have cells with different receptive fields, tuned to different stimulus orientations and movements, which all process the incoming scene in parallel, and in communication with higher-level regions of the brain.
It would be interesting, then, to see what sensory-processing neuroscience and parallel programming could lend one another. Could the architecture of the visual cortex be used to guide design of a parallel architecture for image recognition? Assuming regions like the visual cortex have been evolutionarily optimized, an examination of the parallel architecture of the visual processing system could tell us a lot about how to best organize information flow in parallel computers, and how to format the information which passes between them. Or in the other direction, could design of image-recognition algorithms for massively parallel computers guide experimental analysis of the visual cortex? If we tried to solve for the optimal massively-parallel system for image processing, what computational tasks would the subunits perform, and what would their hierarchy look like-- and could we then look for these computational tasks and overarching structure in the less-understood higher regions of the visual processing stream? It's a bit of a mess because the problem of image processing isn't solved from either end, but that just means each field could benefit from and help guide the efforts of the other.
So! Brains are awesome, and Google should hire neuroscientists. Further reading:
NIPS: Neural Information Processing Systems Foundation
Cosyne: Computational and Systems Neuroscience conference
Introduction to High-Performance Scientific Computing (textbook download)
Message-Passing Interface Standards for Parallel Machines
Google on Machine Learning with Quantum Algorithms
Quantum Adiabatic Algorithms employed by Google
Optimal Coding of Sound
This is the driving motivation behind much of the work that goes into quantum computing. Because bit state in a quantum computer is probabilistic rather than binary, the computer operates in a fundamentally different way, and we can design algorithms which take such differences into account. One vivid example is Grover's Algorithm for searching an unsorted array. Here's a good description from Google labs:
Assume I hide a ball in a cabinet with a million drawers. How many drawers do you have to open to find the ball? Sometimes you may get lucky and find the ball in the first few drawers but at other times you have to inspect almost all of them. So on average it will take you 500,000 peeks to find the ball. Now a quantum computer can perform such a search looking only into 1000 drawers.
So if you were opening one drawer a second, the traditional algorithm would take you an average of six days to run, while the quantum algorithm would take you a little under 17 minutes.
(Now, say each of those million drawers represented a different combination of letters and numbers, and you were trying to find the drawer/combination which corresponded to the password to someone's email account. Encryption standards which would be secure against attacks from a traditional computer are easily bypassed by quantum algorithms.)
While quantum computing still has a ways to go, parallel programming is already providing another alternative to traditional computer architecture. In parallel programming, you split your code up and send it to a number of computers running simultaneously (for our million-drawer problem: say you had 9 other people to help you, you could each search a different set of 100,000 drawers and it would only take 50,000 steps on average for the ball to be found.) So the trick in parallel programming is to figure out the right way to eliminate all the bottlenecks in your code and split up your task across processors as efficiently as possible.
Now, what about a task like image recognition? If you had a couple thousand processors at your disposal and a single image to feed them, what is the most efficient way for your processors to break up that image so that between them they can reconstruct an understanding of what it depicts? You might decide to give each computer a different small piece of the image, and tell it to describe what it sees there-- maybe by indicating the presence or absence of certain shapes within that piece. Then have another round of computers look at the output of this first batch and draw more abstract conclusions-- say computers 3, 19, and 24 all detected their target shape, so that means there's a curve shaped like such-and-such. And continue upwards with more and more tiers representing higher and higher levels of abstraction in analysis, until you reach some level which effectively "knows" what is in the picture. This is how our current understanding of the visual cortex goes-- you have cells with different receptive fields, tuned to different stimulus orientations and movements, which all process the incoming scene in parallel, and in communication with higher-level regions of the brain.
It would be interesting, then, to see what sensory-processing neuroscience and parallel programming could lend one another. Could the architecture of the visual cortex be used to guide design of a parallel architecture for image recognition? Assuming regions like the visual cortex have been evolutionarily optimized, an examination of the parallel architecture of the visual processing system could tell us a lot about how to best organize information flow in parallel computers, and how to format the information which passes between them. Or in the other direction, could design of image-recognition algorithms for massively parallel computers guide experimental analysis of the visual cortex? If we tried to solve for the optimal massively-parallel system for image processing, what computational tasks would the subunits perform, and what would their hierarchy look like-- and could we then look for these computational tasks and overarching structure in the less-understood higher regions of the visual processing stream? It's a bit of a mess because the problem of image processing isn't solved from either end, but that just means each field could benefit from and help guide the efforts of the other.
So! Brains are awesome, and Google should hire neuroscientists. Further reading:
NIPS: Neural Information Processing Systems Foundation
Cosyne: Computational and Systems Neuroscience conference
Introduction to High-Performance Scientific Computing (textbook download)
Message-Passing Interface Standards for Parallel Machines
Google on Machine Learning with Quantum Algorithms
Quantum Adiabatic Algorithms employed by Google
Optimal Coding of Sound
Sunday, November 22, 2009
Delia Derbyshire, Alchemist of Sound
The amazing Delia Derbyshire, pioneer of British electronic music, demonstrating tape loops. A clip from the documentary "Alchemists of Sound" on the history of the BBC Radiophonics Workshop, where Derbyshire worked from 1962-1973.
Derbyshire is best known for her realization of the original Doctor Who theme-- from Wikipedia: Derbyshire's interpretation of Grainer's theme used electronic oscillators and magnetic audio tape editing (including tape loops and reverse tape effects) to create an eerie and unearthly sound that was quite unlike anything that had been heard before. Derbyshire's original Doctor Who theme is one of the first television themes to be created and produced by entirely electronic means. Much of the Doctor Who theme was constructed by recording the individual notes from electronic sources one by one onto magnetic tape, cutting the tape with a razor blade to get individual notes on little pieces of tape a few centimetres long and sticking all the pieces of tape back together one by one to make up the tune. This was a laborious process which took weeks.
From her web site: A recent Guardian article called her 'the unsung heroine of British electronic music', probably because of the way her infectious enthusiasm subtly cross-pollinated the minds of many creative people. She had exploratory encounters with Paul McCartney, Karlheinz Stockhausen, George Martin, Pink Floyd, Brian Jones, Anthony Newley, Ringo Starr and Harry Nilsson.
Friday, November 20, 2009
High Speed Sequencing
This video dedicated to my undergraduate degree in biology, in which it was never deemed necessary to introduce the fact that sequencing technology more sophisticated than the Sanger method exists. This is an animation explaining the process behind Helicos's new single-molecule sequencing technology. Like all other modern sequencing methods, this technique is based on short-read sequences-- DNA is replicated and then broken into millions of tiny fragments (25-50 base pairs at the low end), all of which are sequenced simultaneously. Given about 30-fold coverage of your genome, you can align these fragments to confidently reconstruct it as a single sequence.
Also of note, the Velvet algorithm is one cool sequence assembly program which, instead of aligning DNA fragments by simply looking for overlapping regions between them, plots all the fragment sequences generated onto a De Bruijn graph, and then uses principles of graph theory to condense them into a single sequence. Yay math!
Saturday, October 10, 2009
Urban Speculation Links
Been reading a bit lately on urban architecture and design, which turns out to be a much more active field than I'd have expected. The work I've read comes from an interesting perspective-- there's the creative mindset of art and design students (which also lends itself to an unfortunate affinity for lovely but impractical concept art), mixed with a love of new technology, and an interest in complex city infrastructure and human culture, particularly the way cultural boundaries develop and shift over time and the way behavior is controlled by environment.
While there are certainly some fun ideas floating around, the focus is more on these concepts than their realization, and as such things can get pie-in-the-sky fairly quickly. But if you keep this in mind it can be interesting reading, and it will at the very least introduce to you a new way of thinking about the way we shape and are shaped by our surroundings.
Some introductory links:
While there are certainly some fun ideas floating around, the focus is more on these concepts than their realization, and as such things can get pie-in-the-sky fairly quickly. But if you keep this in mind it can be interesting reading, and it will at the very least introduce to you a new way of thinking about the way we shape and are shaped by our surroundings.
Some introductory links:
- Bldg Blog is a popular blog dedicated to architectural conjecture and urban speculation
- the Architectural League of New York hosts occasional events and exhibits; their current exhibit Toward the Sentient City touches on ubiquitous computing in cities
- Subtopia discusses the impact of architecture on social structure, and the resulting military implications (current posts have mostly been link compilations, but there's a good about page here)
- grinding.be occasionally posts pieces of urban-minded futurism
- and back in June I linked a talk put out by the Complex Terrain Lab on urban warfare and infrastructure
- Also technology-wise (much as I cringe to use half of these buzzwords) concepts discussed include QR codes, wireless sensor networks, geotagging, augmented reality, ubiquitous computing, the Internet of Things, and cloud computing, among others
Monday, September 7, 2009
The New Settlers of Detroit

The economic recession has taken a particularly heavy toll on the American auto industry, and cities like Detroit which were once central to the industry have been gutted by job losses and home foreclosures in the past year. This effect has been so extreme that property in Detroit must practically be given away: Yahoo Real Estate shows dozens of homes around the city selling for mere hundreds of dollars. And still the population of Detroit, a city designed to support roughly 2 million people, has dwindled to less than a million, while the shutdown of many supermarket chains has created a food desert in the city.
Detroit's plight has been well covered in the news, and organizations are already forming to take advantage of the area's collapsed economy. Artists, sustainability enthusiasts, survivalists, and hippie-types in general are coordinating the mass purchase and transformation of land in and around the city. And since this recession coincides with a period of increased interest in locally-grown produce and sustainability, many efforts have a heavy focus on urban farming-- a fact which has received attention from Canada's Office of Urban Agriculture, the Beeb, and NPR among others.
Naturally there's a lot of hype surrounding the whole thing, and it will be interesting to see how this new influx impacts the culture of the city in coming years. For further reading, here are a few people and organizations currently involved in settling the area and documenting their impact:
- Andrew Kemp is a resident of East Detroit who has bought up five lots in his neighborhood and is now farming four of them
- Urban Farming is an NPO which farms vacant lots in Detroit and gives collected produce to the needy
- Detroit UnReal Estate Agency is a group which tracks cultural development in Detroit and inventories cheap property in the area
- the Yes Farm is a collective of artists and urban farmers living and creating in Detroit
- the Power House Project is a social art project attempting to develop an efficient, sustainable home in the city for under $99,000
Friday, August 28, 2009
TinEye

TinEye is a reverse image search engine-- ie you upload a picture from your computer and it'll look for sites that use that picture. Seems to work pretty well, though sadly it was unable to tell me where the above picture came from-- it's been sitting orphaned on my PC for ages. Their Cool Searches page shows some examples of what the site is capable of in terms of image recognition-- impressive stuff. Similar to this, Google has a Similar Images search function, which seems to work pretty well but doesn't seem to support searching uploaded images so far.
Hmm, I wonder what it'd take to make a content search for music-- I'm not sure how input to the search would work, but it'd be an interesting project just to study feature/melody extraction from mp3s. Most music has some sort of regular structure: could you automatically find the hook or the chorus of a pop song? Maybe make a filter that converts complex orchestral sound to pure tones, or even generates sheet music from sound files? Time to do some digging.
Imaging a molecule

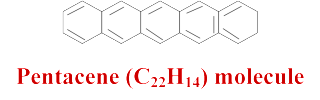
Researchers at IBM announce that the detailed chemical structure of a single molecule has been imaged for the first time.
Thursday, August 20, 2009
Google News timelines
So I've just discovered Google News has an Archive Search feature, which lets you search historical news articles for a given phrase and return a histogram of hits. It makes an interesting way to map the rise and fall of concepts, events, and phrases in the public mind. Here are some queries I've come across that have interesting patterns:
First, some normalization: a search for the, and, a, etc gives us an estimate of the number of articles on record-- gradual uphill increases like those seen here should be attributed to the nature of the data set and not the data itself. (Science!)
There's lots of modern words and phrases we can watch grow into popularity, like outer space and DNA. More subtly, we see the emergence of the adjective global starting in the 1940's, and a sudden rise in popularity of the word deadly in the 1980's (wut?). Robot grows gradually in use over the 20th century, though there is a funny spike in the summer of 1944, which correlates to German use of "robotic" planes to bomb Britain during WW2. And atom shows a boom midway through 1945, of course, though it's curious to note that its appearance in the news is deminished prior to that, during the war-- this could be a result of wartime news censorship, but then if you search science itself, you see that science reporting in general tends to drop during wartime, which could also be a factor.
Then some words are tied to a certain time period-- like fallout shelter and elixir. Others fall from popularity: for some odd reason, the word obituary became wildly unpopular in 1986, while the civil rights movement (I assume) soundly quashed use of the word negro after the late 60's. And lipstick, after rising in popularity starting in the roaring 20's (a phrase which didn't actually take off 'til the 60's-- does that mean 20's culture was to the 60's what baby boomer culture is to the 90's/today?), lipstick suffered a temporary blow in the 1970's, either from the growth of the feminist movement or simply from the fashion of the time.
What other trends are out there?
First, some normalization: a search for the, and, a, etc gives us an estimate of the number of articles on record-- gradual uphill increases like those seen here should be attributed to the nature of the data set and not the data itself. (Science!)
There's lots of modern words and phrases we can watch grow into popularity, like outer space and DNA. More subtly, we see the emergence of the adjective global starting in the 1940's, and a sudden rise in popularity of the word deadly in the 1980's (wut?). Robot grows gradually in use over the 20th century, though there is a funny spike in the summer of 1944, which correlates to German use of "robotic" planes to bomb Britain during WW2. And atom shows a boom midway through 1945, of course, though it's curious to note that its appearance in the news is deminished prior to that, during the war-- this could be a result of wartime news censorship, but then if you search science itself, you see that science reporting in general tends to drop during wartime, which could also be a factor.
Then some words are tied to a certain time period-- like fallout shelter and elixir. Others fall from popularity: for some odd reason, the word obituary became wildly unpopular in 1986, while the civil rights movement (I assume) soundly quashed use of the word negro after the late 60's. And lipstick, after rising in popularity starting in the roaring 20's (a phrase which didn't actually take off 'til the 60's-- does that mean 20's culture was to the 60's what baby boomer culture is to the 90's/today?), lipstick suffered a temporary blow in the 1970's, either from the growth of the feminist movement or simply from the fashion of the time.
What other trends are out there?
Thursday, April 23, 2009
Kurzweil Reading Machine
Huh, I never knew this: according to a profile of Ray Kurzweil in Wired, the LexisNexis database-- now an enormous resource with extensive corporate, legal, and academic use-- grew out of a late 70's venture using Kurzweil's recently-developed character-recognition algorithms to scan legal documents and news articles.
Said character-recognition algorithms are a part of a text-to-speech tool Kurzweil continues to refine; its current incarnation is a software package for Nokia phones which will read aloud to you when held above a page.
Said character-recognition algorithms are a part of a text-to-speech tool Kurzweil continues to refine; its current incarnation is a software package for Nokia phones which will read aloud to you when held above a page.
Wednesday, April 1, 2009
GhostNet
Investigators with Infowar Monitor have recently exposed a vast spy system dubbed GhostNet which has been gathering intelligence information from over 1200 government, military, and NGO computers across 103 countries, mostly in South and Southeast Asia. The system is based almost entirely in China, but it is yet unclear whether it is the work of the Chinese government, independent Chinese citizens, or some outside organization.
A recent New York Times article on the system is full of spooky facts, such as evidence of the system's use against the Dalai Lama and the Tibetan rights movement, and descriptions of its capacities including the ability to activate infected computers' audio and visual recording equipment to covertly eavesdrop on their surroundings.
View the 53-page report detailing the GhostNet investigation here.
A recent New York Times article on the system is full of spooky facts, such as evidence of the system's use against the Dalai Lama and the Tibetan rights movement, and descriptions of its capacities including the ability to activate infected computers' audio and visual recording equipment to covertly eavesdrop on their surroundings.
View the 53-page report detailing the GhostNet investigation here.
Subscribe to:
Posts (Atom)