Saturday, June 19, 2010
David O'Reilly on animating movement
I think the bit on movement trajectories in animation is brilliant. Natural human movements also follow this kind of smooth trajectory; studies of motor planning (eg here) have found that this sort of movement is optimally designed to minimize energy expenditure. It’s so great when artists figure out how to convey different feelings just by making these subtle tweaks to the textures and physics of the real world, I think it can really tell us a lot about our own perception.
Also: vectorpunk? Seriously, BoingBoing? Vectorpunk.
Monday, May 17, 2010
Hemispatial neglect

Drawings copied by a patient with allocentric hemispatial neglect, in which damage to attention centers in the frontal or temporal lobes causes subjects to only perceive one half of every object.
Sunday, May 9, 2010
Scott and Scurvy
Reading Scott and Scurvy, a fascinating post on Idle Words about the scurvy which plagued Robert Scott's 1911 expedition to the South Pole:
Now, I had been taught in school that scurvy had been conquered in 1747, when the Scottish physician James Lind proved in one of the first controlled medical experiments that citrus fruits were an effective cure for the disease. From that point on, we were told, the Royal Navy had required a daily dose of lime juice to be mixed in with sailors’ grog, and scurvy ceased to be a problem on long ocean voyages.
But here was a Royal Navy surgeon in 1911 apparently ignorant of what caused the disease, or how to cure it. Somehow a highly-trained group of scientists at the start of the 20th century knew less about scurvy than the average sea captain in Napoleonic times. Scott left a base abundantly stocked with fresh meat, fruits, apples, and lime juice, and headed out on the ice for five months with no protection against scurvy, all the while confident he was not at risk. What happened?
It's a fascinating story of how medical practice which lacks knowledge of underlying causes can become distorted over time. It's also kind of heartbreaking to read about the polar missions failing again and again all because they're working from the wrong model of scurvy as a disease.
Now, I had been taught in school that scurvy had been conquered in 1747, when the Scottish physician James Lind proved in one of the first controlled medical experiments that citrus fruits were an effective cure for the disease. From that point on, we were told, the Royal Navy had required a daily dose of lime juice to be mixed in with sailors’ grog, and scurvy ceased to be a problem on long ocean voyages.
But here was a Royal Navy surgeon in 1911 apparently ignorant of what caused the disease, or how to cure it. Somehow a highly-trained group of scientists at the start of the 20th century knew less about scurvy than the average sea captain in Napoleonic times. Scott left a base abundantly stocked with fresh meat, fruits, apples, and lime juice, and headed out on the ice for five months with no protection against scurvy, all the while confident he was not at risk. What happened?
It's a fascinating story of how medical practice which lacks knowledge of underlying causes can become distorted over time. It's also kind of heartbreaking to read about the polar missions failing again and again all because they're working from the wrong model of scurvy as a disease.
Saturday, May 8, 2010
Frequency components of music
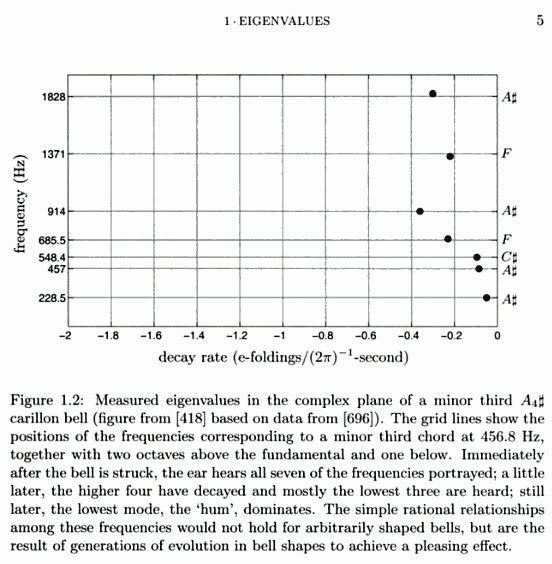
From Spectra and Pseudospectra; click for full size.
Measured eigenvalues in the complex plane of a minor third A4# carillon bell. The grid lines show the positions of the frequencies corresponding to a minor third chord at 456.8 Hz. together with two octaves above the fundamental and one below. Immediately after the bell is struck, the ear hears all seven of the frequencies portrayed; a little later, the higher four have decayed and mostly the lowest three are heard; still later, the lowest mode, the 'hum', dominates. The simple rational relationships among these frequencies would not hold for arbitrarily shaped bells, but are the result of generations of evolution in bell shapes to achieve a pleasing effect.
Seems like this format could make a nice interface for designing new sounds; someday I'd like to get around to recreating it.
Thursday, April 29, 2010
ATP Metabolism
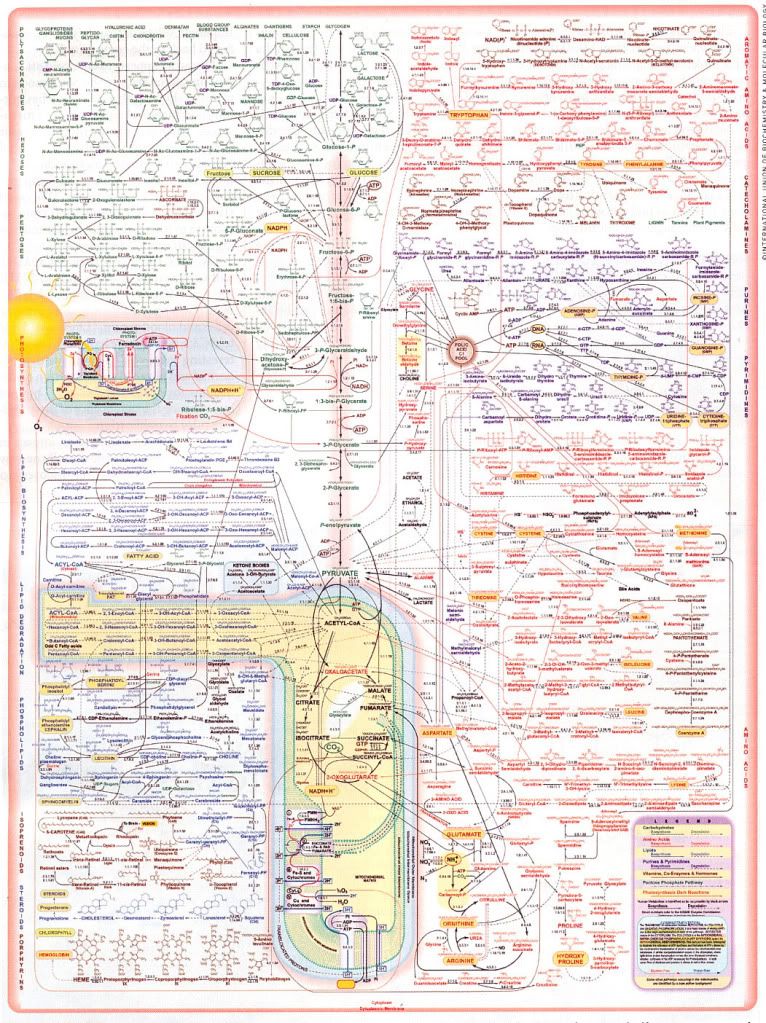
And on the subject of overwhelming biological data, this is the IUBMB-Nicholson chart of all the metabolic pathways that go into ATP management in mitochondria and chloroplasts, ATP being the basic energy currency of biological systems. There's a browser-crashing full sized pdf at the link, or click the above thumbnail for a jpg.
Friday, April 23, 2010
The Long Tail of Life
Saved for future reference from kottke.org:
the Long Tail of Life: During an 11 month study in 2007, scientists sequenced the genes of more than 180,000 specimens from the Western English Channel. Although this level of sampling "far from exhausted the total diversity present," they wrote, one in every 25 readings yielded a new genus of bacteria (7,000 genera in all).
See also: Venter sequences the Sargasso Sea (and download the dataset here!); a review on the emerging field of metagenomics; genomic databases at NCBI (sequences of everything from the human genome to three strains of ebola); Helicos high-speed sequencing; a nice powerpoint on next-gen short-read sequencing and sequence assembly (including notes on Eulerian walks on De Bruijn graphs, the method used by sequence assembly algorithms like Velvet.) Man, guys, sequencing is the coolest.
the Long Tail of Life: During an 11 month study in 2007, scientists sequenced the genes of more than 180,000 specimens from the Western English Channel. Although this level of sampling "far from exhausted the total diversity present," they wrote, one in every 25 readings yielded a new genus of bacteria (7,000 genera in all).
See also: Venter sequences the Sargasso Sea (and download the dataset here!); a review on the emerging field of metagenomics; genomic databases at NCBI (sequences of everything from the human genome to three strains of ebola); Helicos high-speed sequencing; a nice powerpoint on next-gen short-read sequencing and sequence assembly (including notes on Eulerian walks on De Bruijn graphs, the method used by sequence assembly algorithms like Velvet.) Man, guys, sequencing is the coolest.
Monday, April 12, 2010
Bicycle Built for Two Thousand
Bicycle Built For 2,000 is comprised of 2,088 voice recordings collected via Amazon's Mechanical Turk web service. Workers were prompted to listen to a short sound clip, then record themselves imitating what they heard. (more info)
(Daisy Bell was famously performed by an IBM 704 in 1962, in the world's first example of musical speech synthesis-- which is probably why Kubrick chose it for the end of 2001 as well.)
(Daisy Bell was famously performed by an IBM 704 in 1962, in the world's first example of musical speech synthesis-- which is probably why Kubrick chose it for the end of 2001 as well.)
Monday, March 1, 2010
The Grande Armée Invades Russia

Charles Joseph Minard was a mathematician, a civil engineer, and a pioneer in the field of information graphics; his most famous work is the above chart, which he created in 1869. It tells the tale of Napoleon's disastrous invasion of Russia in 1812: The width of the line represents the size of the Grande Armée from the crossing of the Niemen river to the deserted streets of Moscow and back, with temperatures during the return trip plotted along the bottom. At its peak, the Grand Armée numbered 690,000 men (422,000 at the start of this invasion), and was the largest army assembled to that point in European history.
Thursday, January 7, 2010
2020 Visions
Nature's interviews of prominent scientists on their visions of scientific progress in the next decade. Exciting stuff!
Saturday, January 2, 2010
Hubble Advent Calendar

The 2009 Hubble Telescope Advent Calendar.
The sublime moves; the expression of a person experiencing the full sense of the sublime is serious, at times rigid and amazed. On the other hand, the vivid sense of the beautiful reveals itself in the shining gaiety of the eyes, by smiling and even by noisy enjoyment. The sublime, in turn, is at times accompanied by some terror or melancholia, in some cases merely by quiet admiration and in still others by the beauty which is spread over a sublime place. The first I want to call the terrible sublime, the second the noble, and the third the magnificent. Deep loneliness is sublime, but in a terrifying way.
The sublime must always be large; the beautiful may be small. The sublime must be simple; the beautiful may be decorated and adorned. A very great height is sublime as well as a very great depth; but the latter is accompanied by the sense of terror, the former by admiration. Hence the one may be terrible sublime, the other noble.
A long duration is sublime. If it concerns past time it is noble; if anticipated as an indeterminable future, it has something terrifying.
(on the Beautiful and the Sublime.)
Subscribe to:
Comments (Atom)